Over the last few days, I’ve been reading a lot about why it’s still so painful to run open source models on Google TPUs.
Even with their massive performance potential, TPUs still aren’t in the spotlight the way NVIDIA GPUs are. So why does NVIDIA still dominate roughly 80–85% of the market?
I was curious about this, so I started digging deeper. In this article, I’ll break down everything I learned step by step.
Let’s start with, what is a GPU, really?
Imagine you need to add 1000 pairs of numbers. A CPU is like a genius professor — very smart, does one calculation brilliantly, then the next. A GPU is like 10,000 kindergarteners — each one does a tiny, dumb addition simultaneously. For matrix math (which is ALL a neural network is), kindergarteners win.
GPUs were built for graphics — rendering pixels. A pixel color is just a little matrix multiplication. Neural networks are also just matrix multiplications. So GPUs accidentally became the perfect AI hardware.
You might be wondering, What is a TPU then?
Google looked at GPUs and said: "These are good, but they still do too many things. We only care about one thing: matrix multiply. Let's build a chip that does ONLY that, insanely fast."
A TPU (Tensor Processing Unit) is an ASIC (Application-Specific Integrated Circuit) designed as a Systolic Array whose entire silicon is devoted to one operation: matrix multiplication of fixed-size tiles. That's it. It's not flexible. It's a factory that makes exactly one product, but makes it faster than anyone else.
TPUs got a secret weapon, it’s called Systolic Array, but what the heck is that and how it makes TPUs more efficient than GPUs?
Picture a grid of tiny calculators all passing numbers to their neighbor like an assembly line. Each cell receives a number from the left and another from above, multiplies them, adds to its running total, and passes the result forward. This is called a systolic array.
Numbers flow →→→→→→→→
↓ [×] [×] [×]
↓ [×] [×] [×]
↓ [×] [×] [×]
↓↓ ↓↓ ↓↓
Results fall outThis is one of the biggest reasons TPUs are so efficient for AI workloads. Neural networks are mostly giant matrix multiplications repeated billions of times, and systolic arrays are designed specifically for this pattern. Instead of fetching data again and again from memory for every operation, TPUs try to keep data flowing continuously through the chip. Once numbers enter the array, they get reused many times as they move across the processing units.
This is very different from how GPUs usually work. GPUs are more general purpose. Thousands of CUDA cores independently pull data from memory, process it, and write results back. That flexibility is what made GPUs dominate AI in the first place because almost any model architecture or custom kernel can run on them. But constantly moving data between compute units and memory is expensive in both latency and power consumption.
TPUs optimize for the opposite tradeoff. They sacrifice flexibility to reduce memory movement as much as possible because, in modern AI hardware, moving data is often more expensive than the computation itself. A multiplication is cheap. Fetching numbers from memory over and over again is not.
That’s why TPUs can deliver incredible performance per watt when the workload fits perfectly into their execution model. But there’s a catch. Everything needs to be static, predictable, and shaped correctly ahead of time. If tensor shapes keep changing, operations become irregular, or the computation graph is too dynamic, the entire flow becomes inefficient and the assembly line starts breaking down.
But what are tensor shapes ??
Non technical explanation
So far we have understood, we need static tensor shapes to run models on TPUs because of their architecture but you might be wondering what are these shapes we’re talking about. Let’s understand them in non technical way.
In AI, data travels in boxes called tensors. A shape is the dimensions of that box. A shape of [Batch Size: 4, Token Length: 512] means you are feeding the AI 4 sentences, and each sentence is 512 words long.
The Assembly Line Analogy: GPU vs. TPU
GPU: A GPU acts like a conveyor belt with a worker. The worker processes the box.
TPU: A TPU operates like a machine that drops stampers into slots. If you tell the TPU, "We are using shape 512," it locks its internal data pathways into a rigid configuration. If you send a box of size 300, the TPU cannot process it. To fix this, the TPU must stop completely, clear its memory, and restart. This is called re-compilation, and it ruins performance.
Technical Explanation
Let’s understand what is CUDA, CUDA (Compute Unified Device Architecture) in simple terms is about how you write code to run on NVIDIA GPUs
It’s a proprietary computing platform and programming model for executing parallel tasks on GPUs. Both “platform“ and “programming model“ are broad definitions; it’s easier to look at CUDA in its component parts:
CUDA kernel: A user-defined function that executes parallelized code on the GPU
CUDA graph: A directed acyclic graph (DAG) of kernels and other GPU operations for optimizing repeated workflows.
CUDA driver: A low-level interface between the application and the GPU hardware to manage memory and execution.
CUDA runtime: A developer-facing API for launching kernels and managing memory.
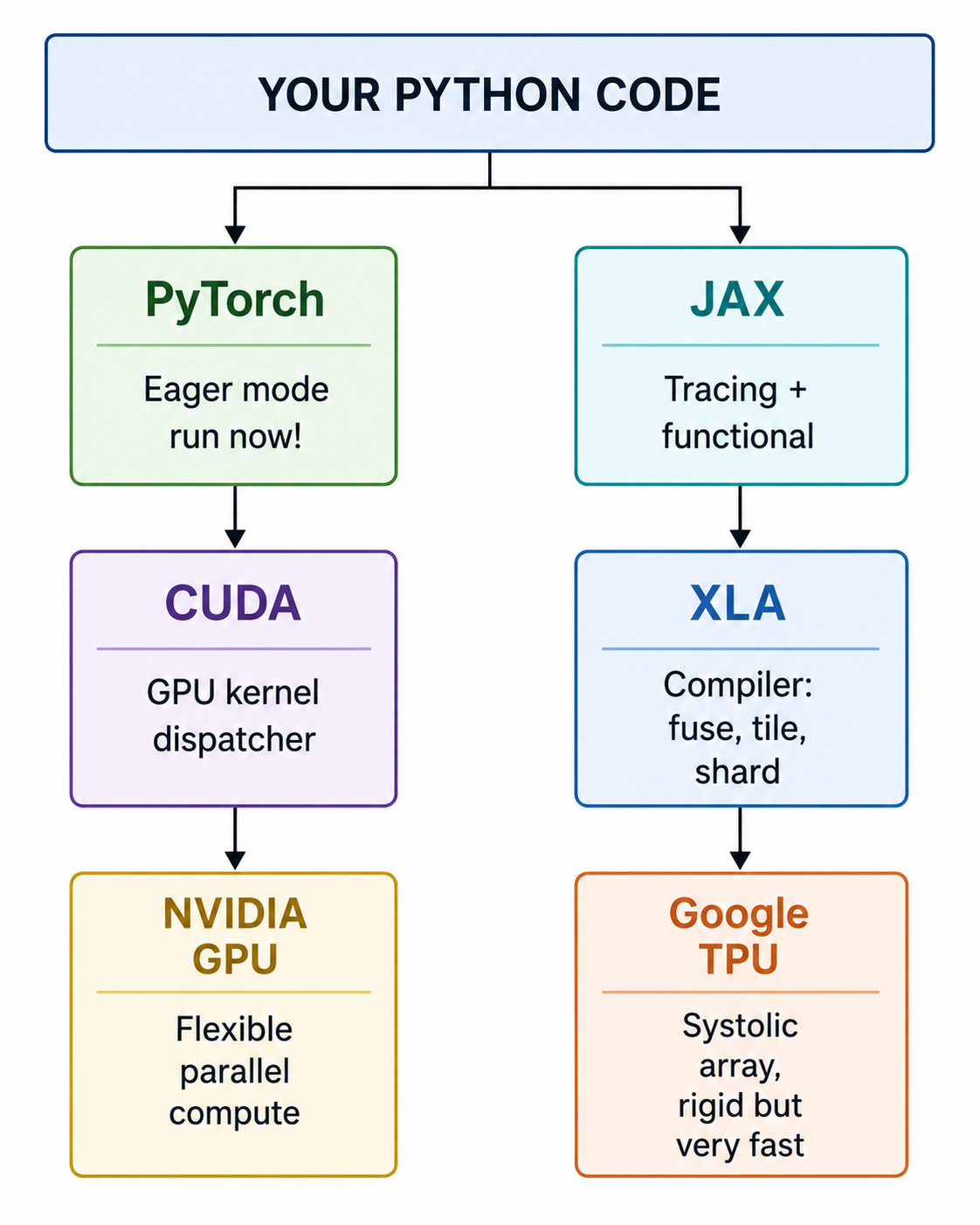
Your Python code
↓
PyTorch
↓
CUDA (C++ layer)
↓
NVIDIA GPU hardwareCUDA is imperative — it runs your instructions line by line, as you write them, in the order you write them. Very natural for programmers.
PyTorch is a Python library that wraps CUDA, it’s friendly face of CUDA. When you write:
output = weight_matrix @ input_vector # matrix multiplyPyTorch immediately tells CUDA: "hey GPU, do this multiply right now." The GPU does it. Done. Very intuitive — you write code, it runs, you see results instantly. This is called eager execution.
JAX (Google's library)
JAX (Just After eXecution — or more precisely, it's a play on "Autograd + XLA") is Google's Python library for ML math. It looks a lot like NumPy:
import jax.numpy as jnp
output = jnp.dot(weights, inputs) # looks the same!But internally it works completely differently. JAX is a tracing compiler. When you write that line, JAX doesn't run it immediately. It traces your entire function first, builds a mathematical graph of everything you want to do, then hands that whole graph to XLA
XLA (Accelerated Linear Algebra) is a compiler — think of it as a master architect. JAX hands it your entire computation graph and XLA:
1. Looks at everything holistically
2. Fuses operations together (why write to memory twice if you don't have to?)
3. Figures out exactly how to tile data across the TPU's systolic array
4. Generates low-level machine code perfectly shaped for the hardware
Your Python/JAX code
↓
JAX traces your function (builds a graph)
↓
XLA compiles the graph
↓ (optimization, tiling, fusion happens HERE)
TPU hardware (or GPU!)XLA can also compile for GPUs — but it must compile. You cannot run "raw" code on a TPU.
So why can't PyTorch just run on TPUs?
| Feature | PyTorch | TPU Requirement |
|------------------|----------------------|-------------------------------------|
| Execution model | Eager (run now) | Must compile first |
| Operation support| Thousands of ops | Only XLA-supported ops |
| Memory layout | Flexible | Rigid tiling required |
| Debugging | Run → see error | Compile → run → error (late) |
| Dynamic shapes | Easy | Very hard (must recompile) |PyTorch's killer feature — that you can write print() in the middle of a model, change shapes dynamically, use Python if-statements freely — is exactly what makes it incompatible with TPUs.
TPUs need to know the entire computation plan before a single number moves. It's like the difference between:
PyTorch: improvised jazz — musicians respond to each other in real time
TPU: a symphony orchestra — everyone has a fixed score, perfectly timed, no improvising
Google built torch_xla — a library that tries to make PyTorch work on TPUs. It intercepts PyTorch operations, queues them up, and lazily compiles them with XLA. It works, but:
It's slow to compile
Not all PyTorch ops are supported
Dynamic shapes (variable-length sequences) are a nightmare
The debugging experience is terrible
This is why you mostly see JAX on TPUs and PyTorch on GPUs — they were each built for their hardware's philosophy.
Final mental model to take home